Hi everyone! My name is Ravi, a software engineer with over a decade of experience in backend systems and a pinch of frontend expertise. Today, we’re diving deep into a system design challenge for building a web crawler that can scale up to 10,000 machines strategically scraping the web. Whether you’re a system design beginner or preparing for an interview with one of the FAANG companies, this breakdown will help you confidently answer any web crawler interview question while crafting a scalable and performant design.
Ready to explore the intricate details of web crawling? Let’s get started! 👊
Understanding the Web Crawler Problem
At its core, a web crawler is a tool that systematically browses the web, collecting information on indexed pages, which can later be used in search engines or other applications. Your task may look deceptively simple when asked in an interview, such as:
“Design a distributed web crawler that processes 1 billion pages efficiently.”
But let’s break this down. A crawler starts with a seed URL, follows links on that page, fetches the content, and keeps repeating this process. The complexity arises when we consider:
- Scale: Processing billions of pages.
- Performance: Staying performant even as scale grows.
- Storage: Handling terabytes (or more) of data per week.
- Deduplication: Avoiding re-fetching the same content or URLs.
- Politeness Policies: Respecting websites’ crawling rules (e.g.,
robots.txt).
Functional and Non-Functional Requirements
Here’s what the recruiter is looking for when asking you to design a web crawler:
Functional Requirements
- Crawling Schedules: Regularly revisit dynamic websites (e.g., news sites) while deprioritizing static ones (e.g., company home pages).
- URL Deduplication: Avoid duplicate URLs using efficient algorithms like Bloom Filters or hashed checksums.
- Content Extraction: Separate URLs on crawled pages and extract useful data (HTML + metadata).
- Politeness: Avoid overwhelming web servers by spacing out requests.
Non-Functional Requirements
- Scalability: Design should scale linearly as the number of worker nodes (machines) increases.
- Availability: High uptime to ensure crawling continues without bottlenecks.
- Performance: Fast crawling within bandwidth limitations (e.g., 10PB of data every 7 days).
- Security: Throttle requests to avoid being identified as a botnet.
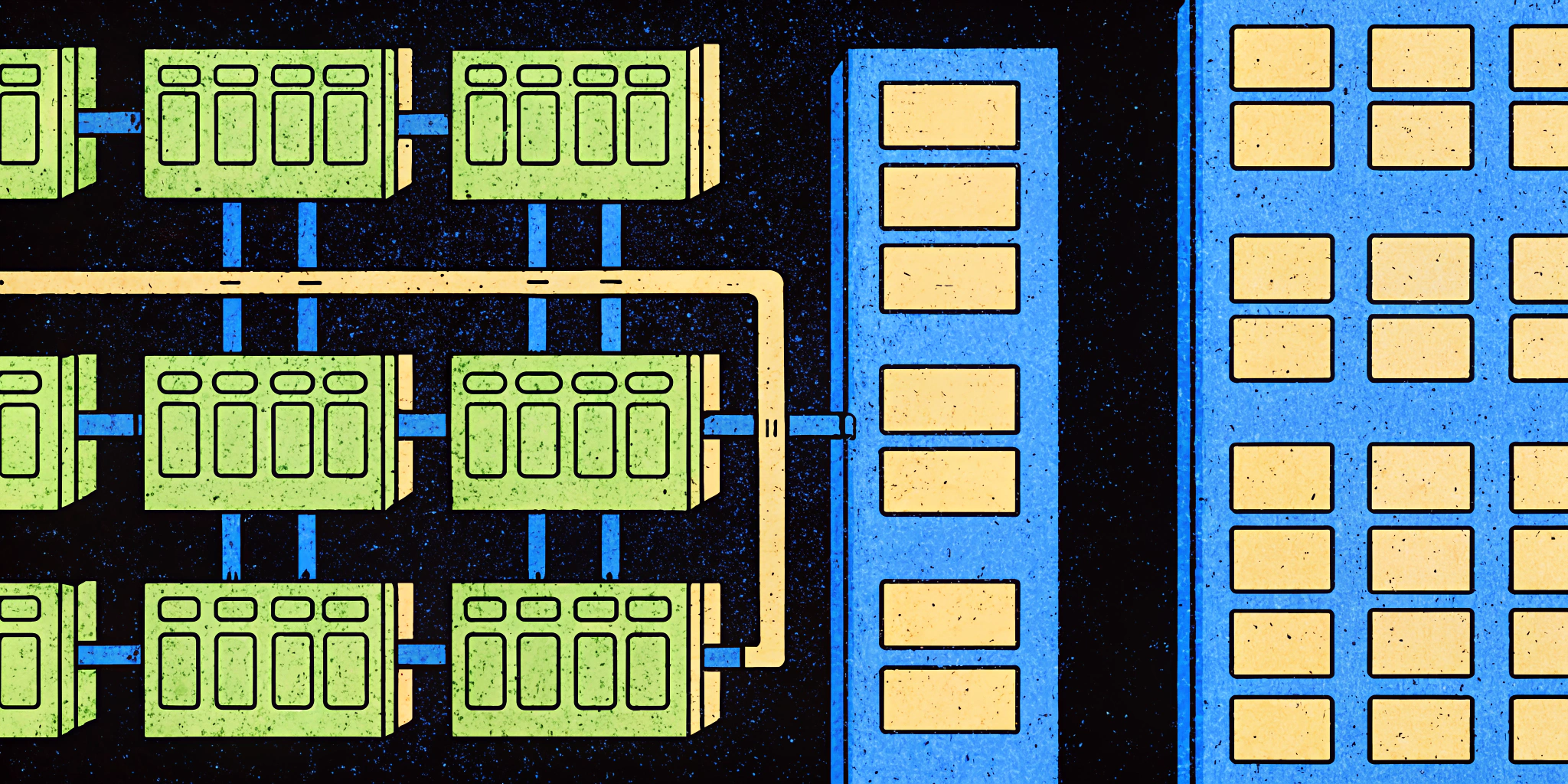
High-Level Architecture Overview
Let’s simplify our distributed web crawler design by breaking it into four core components:
- Scheduler: Handles crawling priorities, schedules URLs for workers, and respects politeness rules.
- Fetcher: Responsible for downloading web pages and passing their content downstream.
- Extractor: Parses fetched HTML to extract relevant data (e.g., URLs and metadata).
- Storage: Stores data, including raw HTML, URLs, and metadata, in scalable storage solutions (e.g., AWS S3 for objects).
Let’s visualize this architecture (scroll for the diagram 👇):
| Component | Role | Implementation Details |
|---|---|---|
| Scheduler | Manages the crawling queue | Tracks repeated URLs using Bloom Filters. |
| Fetcher | Downloads HTML and static files | Designed to respect rate-limits and delays. |
| Extractor | Parses HTML documents for nested URLs | Uses checksum to ensure that stored content is unique. |
| Storage | Persists page data, logs errors, etc. | Combines SQL/NoSQL with object storage. |
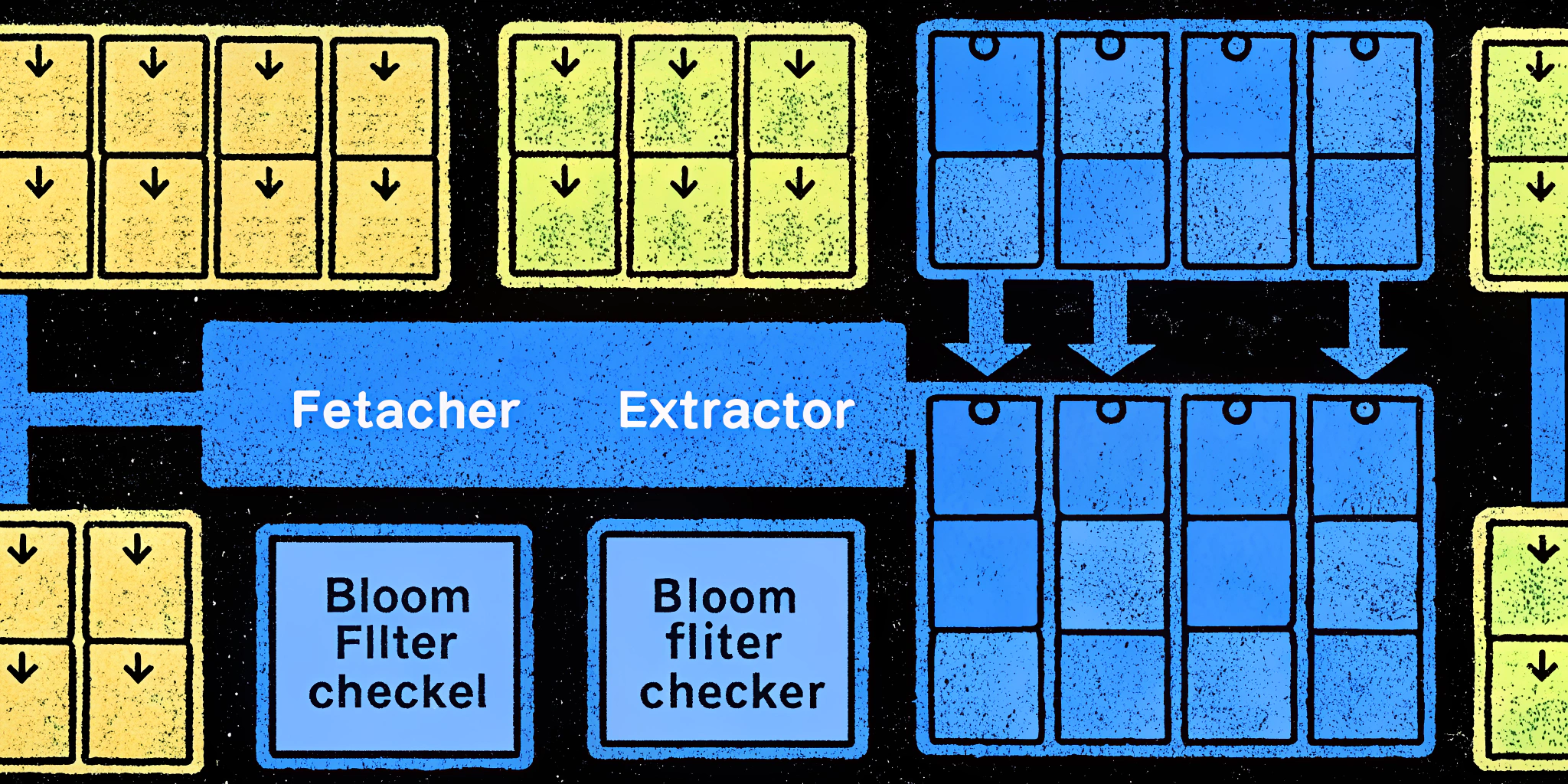
Key Challenges & Advanced Techniques
Building a high-scale crawler isn’t complete without tackling these advanced challenges:
Avoiding Duplication
When dealing with billions of pages, duplicate crawling wastes bandwidth and storage. Here’s what works:
| Technique | How It Works | Pros |
|---|---|---|
| Bloom Filters | Probabilistic check if URL is seen | Memory efficient; fast lookups. |
| Content Checksums | Hash each page’s content (e.g., md5) | Ensures unique data in storage. |
Using Bloom filters, you can efficiently decide whether to revisit a URL. When combined with checksums, the system can avoid saving duplicate content with different URLs.
Prioritizing URLs
Some websites demand higher frequency crawling than others. For instance, news websites must be refreshed every few minutes, whereas company blogs might only require weekly updates.
Approach:
- Use a Priority Queue for scheduling.
- Assign each URL a priority score based on frequency.
- Store rules and robots.txt in an RDBMS/NoSQL database for quick lookups.
Handling Crawling Schedules
We calculate a target system size of 10PB/week for storage with:
- URL Schedules: E.g., visit top-tier URLs every 2 hours.
- Politeness Policies: Respect
robots.txton every crawl. - Utilize distributed cron-like schedulers, e.g., Apache Airflow.
Scaling to 10K Machines
Achieving distribution isn’t optional if we’re scaling to 10,000 nodes. Here’s how to handle it:
- Horizontal Scaling: Use frameworks like Apache Kafka for worker communication and AWS EC2 Spot Instances for worker scaling.
- Load Balancing: Balance fetchers across nodes with services like HAProxy or built-in Kubernetes ingress solutions.
- Sharding: Partition URLs by either domain or a hash-mod scheme to optimize resource efficiency across workers.
- Consistency: Enable strong consistency in schedulers using consensus algorithms like Paxos or Raft.

Addressing Security and Ethical Concerns
Crawling inherently introduces security risks. To avoid problems:
- Respect Robots.txt Files: Adhere strictly to website-published guidelines.
- Avoid Overloading Servers: Implement throttle controls and rate limiters as part of fetcher design.
- Monitor for Abuse: Track anomalous behaviors that might flag the system as malicious (e.g., exponential crawling).
Interactive Tools: Ninjafy AI Support for System Design Interviews
If interviews intimidate you, here’s an amazing tool I highly recommend—Ninjafy AI. It is packed with industry-specific knowledge and uses advanced mock interviews to simulate real-life system design questions.
🚀 Features of Ninjafy AI:
- Mock Interview Practice: Test yourself with dynamic questions like scaling web crawlers.
- Personalized AI Models: Tailored feedback based on your interview style and career history.
- Live Feedback in Real Time: Correct mistakes before finishing.
Fun Fact: More than 39% of Ninjafy users secure “dream job offers” with top tech firms. Since switching to Ninjafy, I’ve personally noticed a marked improvement in how I handle scalable system design questions!
Conclusion
Designing a 10K Machine Web Crawling System is more than sketching architecture. You must think critically about performance, deduplication, and ethical usage to succeed in interviews and real-world applications. By mastering Bloom Filters, sharding, and distributed systems, you can build a scalable crawler that performs at an industry-grade level.
Got more insights or facing specific challenges while preparing? Drop your comments below, and let’s discuss! 🚀

