Introduction
Hi there, I’m Alex, an experienced software engineer, and today we’re going to deep dive into a hugely fascinating topic: building a 10k machine distributed web crawling system. Whether you’re preparing for a system design interview or are genuinely curious about engineering at scale, this blog lays it all out for you! 🕸️
Web crawlers, also called spiders or bots, are software designed to systematically browse and index web pages. They’re the backbone of search engines, data analytics systems, and even malware-detection tools. The key question is, how do you design one that works at scale – say, across 50 billion web pages spread across 500 million websites? Let’s find out!
What You’ll Learn
- What a web crawler is and why you should care.
- Five critical use cases for web crawlers (from search engines to keyword tracking).
- Architecture deep dive: Breaking down the components of a scalable crawler.
- How to implement politeness, rate limiting, and priority queues.
- Storage strategies for petabytes of data.
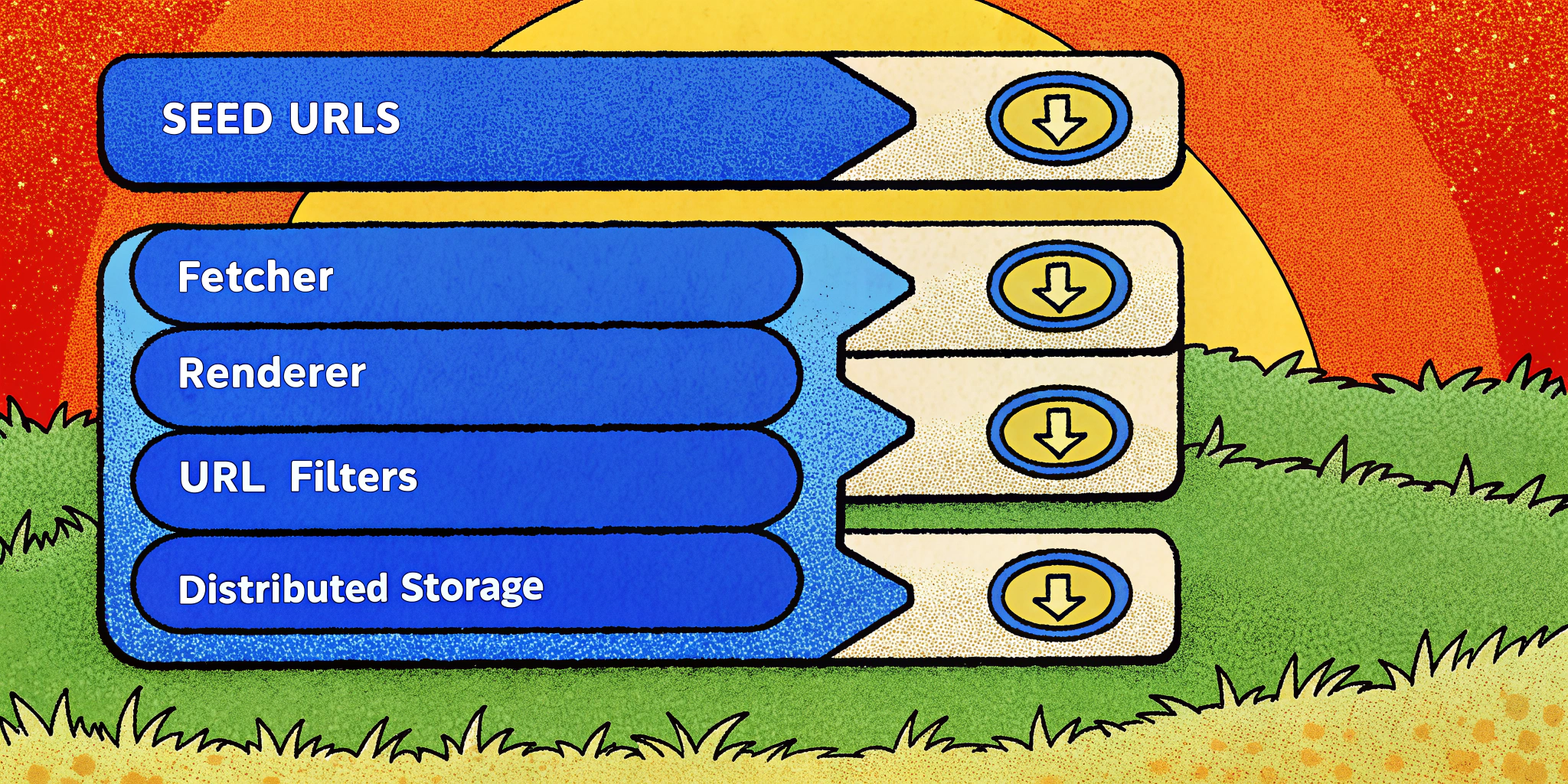
What Is a Web Crawler (And How Does It Work)?
At a high level, a web crawler starts with a set of seed URLs. It visits these URLs, extracts the page content, finds additional URLs on the page, and continues recursively until certain limits (time or depth) are met. Think of it as a snowball rolling downhill, gathering more and more data.
How Does It Work?
- The crawler starts with seed URLs (usually popular or known sites).
- It fetches the content (usually just HTML and CSS data, skipping large images or static files to minimize bandwidth).
- Extracts and normalizes new URLs (using robust filtering methods).
- Rates and prioritizes URLs for crawling (determined by frequency of updates, site importance, etc.).
- Stores the pages in a persistent and distributed storage system for indexing or processing.
📊 Example: Google’s crawler processes 50 billion pages every month, optimizing for freshness (news sites every hour) and completeness.
Key Use Cases for Web Crawlers
Web crawlers power everything from search engines to cybersecurity tools. Here are the top five use cases:
| Use Case | Description |
|---|---|
| Search Engines | Google, Bing, and DuckDuckGo use crawlers to discover and index web pages, helping users surface relevant results within milliseconds. |
| Copyright Violation | Tools like Copyscape can identify websites illegally hosting copyrighted materials (e.g., pirated songs, videos, or articles). |
| Keyword-Based Scraping | Stock market aggregators or SEO tools scrape content related to specific topics, like “S&P 500 news.” |
| Malware Detection | Detect phishing or cloned websites, ensuring user safety (e.g., scanning for fake Gmail login pages). |
| Web Analytics | Data scientists use crawlers to analyze the web’s structure, study user behavior trends, or collect data for machine learning models. |
Challenges in Scaling to Billions of Pages
The Scale 📈
- ~500M functional websites
- ~50 billion pages total (~100 pages/website)
- ~120 KB average page size → 6+ petabytes of storage
To handle this volume, you need to design a distributed system that satisfies high concurrency, low latency, and scalability.
Top Problems
- Politeness Policies: Avoid overloading web servers with excessive requests.
- Duplicate Detection: Avoid wasting resources by re-processing duplicate or identical content.
- Storage Overhead: Efficiently store metadata and content without breaking the bank.
System Design: Building a Scalable Web Crawler
Let’s now dive into the actual architecture to build a 10k machine distributed web crawler.
1. Seed URLs and Priority Management
Seed URLs initiate your crawl. Ideally, these come from diverse sectors like news, finance, blogs, etc. Crawlers use a priority queue (built using heaps) to ensure high-priority URLs (e.g., news sites) are revisited frequently.

- Politeness Queue: Prevent multiple threads from hammering the same domain simultaneously.
2. URL Fetching and Rendering
Modern websites are often single-page applications (SPAs), requiring a JavaScript engine to render their content. Use tools such as Puppeteer for server-side rendering.
Optimization: Assign fetchers and renderers in a 4:1 ratio to minimize bottlenecks.
3. Politeness Policy: Avoiding Server Overload
Respect each site’s rate limits with delays (e.g., 1 request/5 seconds for example.com).
| Politeness Rule | Implementation |
|---|---|
| Rate Limiting | Use robots.txt to adjust crawl frequency appropriately. |
| Per-Host Queue | Assign URLs to specific queues based on their domain (enforced by politeness component). |
| Retry Policies | Retain failing URLs and retry after a cooldown period. |
4. Detecting Duplicates
30% of the internet is duplicate content! Use bloom filters or advanced semantic hashing algorithms like SimHash to spot duplicate URLs/pages efficiently.
| Technique | When to Use |
|---|---|
| Bloom Filters | Fast, lightweight detection of duplicate URLs in large datasets. |
| SimHash | Detect near-duplicate pages with variations in content. |
| Full Hash Validation | For highly similar sites, compare MD5 or SHA hashes of page content. |
5. Distributed Caching and Storage
With ~6PB+ of data, efficient storage is critical.
| System | Pros |
|---|---|
| HDFS (Hadoop) | Great for distributed file storage but struggles with small files. |
| Amazon S3 / Min.IO | Highly reliable object storage for petabytes of unstructured data. |
| Google BigTable | Ideal for storing metadata with consistent read/write speeds. |
How to Ace System Design Interview Questions on Web Crawlers
System design interviews often expect aspirants to discuss scalability, consistency, reliability, and extensibility. Here’s your cheat sheet:
| Question | Answer/Explanation |
|---|---|
| How do you prioritize URLs to crawl? | Use a priority queue based on historical data (news = high priority, static content = low). |
| How to handle 10k threads in parallel? | Split workloads between crawlers and renderers; use consistent hashing to distribute storage. |
| Is rate limiting necessary? Why? | Yes. Avoid breaking external servers and respect politeness policies stated in robots.txt. |
| How to store such large data? | Use distributed file systems like Hadoop HDFS, S3, or Min.IO with metadata indexes for fast lookups. |
For enhanced practice, I recommend running mock interviews through tools like Ninjafy AI. It gives instant feedback on your answers, helping you fine-tune weak areas before you hit real interviews.
Scaling Lessons from Real-World Examples
What do Google, Bing, and DuckDuckGo have in common? They’ve all nailed distributed crawling.
| Feature | Challenges Solved | |
|---|---|---|
| Duplicate Detection | SimHash for content comparison. | Save 30% of crawling bandwidth by identifying copycat pages. |
| Rate Limiting | Heaps + per-host queues | Ensure requests don’t parallelize to same site. |
| Storage | GFS / BigTable | Efficiently index billions of pages with metadata. |
Conclusion: Building for Scalability and Beyond
To successfully build scalable web crawling infrastructure at the 10k machine level, you’ll need to:
- Carefully architect for politeness, prioritization, and rate-limiting.
- Optimize storage solutions for billions of pages across petabytes of data.
- Leverage distributed systems for fault tolerance and increased throughput.
If your next system design interview asks about this topic, you’re going to ace it like a pro. And don’t forget to explore tools like Ninjafy AI to simulate live system design scenarios with AI-powered coaching.

