Introduction 🚀
Hi there! I’m Raj, a Machine Learning Engineer at Snapchat, where I work extensively on generative AI projects. Machine Learning (ML) interviews can be daunting, especially with the vast ocean of concepts you’ll need to navigate. Whether it’s training data, gradient descent, or preparing for unexpected challenges like exploding gradients—getting a grasp of these fundamental topics is essential to ace your interview.
Today, I’ll guide you through key ML concepts frequently discussed in interviews, enriched by real-world insights and applicable strategies you can use for your next technical assessment. Let’s turn those hypothetical scenarios into success stories together! Sound good? 😀

1. What is Training Data vs. Testing Data? 🧩
Quick Answer:
Training data teaches an algorithm to recognize patterns, while testing data evaluates the algorithm’s performance on unseen examples.
Example:
Let’s say you’re building a spam email filter.
- Training Data: Emails labeled as “spam” or “not spam” are processed by your model to adjust its internal weights and parameters.
- Testing Data: NEW, unseen emails are used to gauge how well your model distinguishes spam from non-spam.
Key Insight: Testing on training data may overestimate your model’s performance—because the model already “knows” that data!
2. How to Tune Hyperparameters vs. Model Parameters? 🎛️
Snippet:
- Model parameters (e.g., weights and biases): Learned during training.
- Hyperparameters (e.g., learning rate, number of layers): Set externally and optimized on validation data.
Strategy:
- Split your dataset:
- Training set: For model learning.
- Validation set: For hyperparameter tuning.
- Testing set: For final evaluation.
- Optimize hyperparameters like learning rate and dropout rates based on validation set performance.
Tools for Hyperparameter Tuning:
| Method | Strengths | Weaknesses |
|---|---|---|
| Grid Search | Exhaustive and thorough | Time-consuming |
| Random Search | Faster alternative | Not as comprehensive |
| Bayesian Optimization | Learns to improve searches | Computationally expensive |
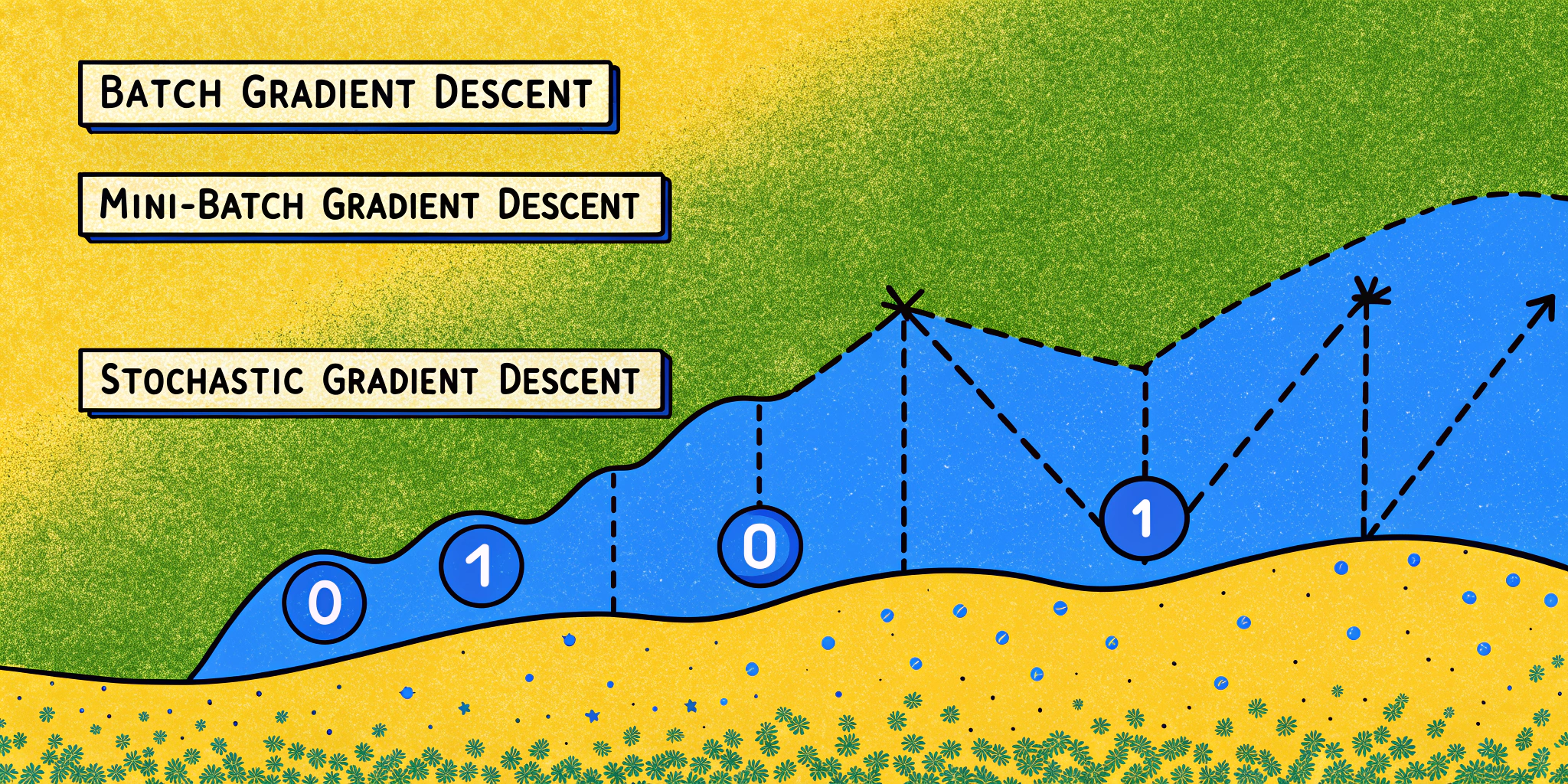
3. Understanding the Three Gradient Descent Techniques 📉
Gradient Descent is a cornerstone of ML training. There are three main flavors:
| Technique | Data Usage | Pros | Cons |
|---|---|---|---|
| Batch | Entire dataset per update | Accurate gradients | High memory cost |
| Mini-batch | Subset (e.g., size of 64) | Balances speed and memory | Still requires some tuning |
| Stochastic | Single example per update | Fast, regularizes noise | More fluctuation in updates |
4. Why Does Model Performance Go South in Production? 🏭
Concept Drift:
Sometimes, the relationship between input features (X) and the target variable (Y) shifts over time, causing “Concept Drift.” For instance:
- Training set = e-commerce data from Summer 🏖️.
- Production data = Holiday shopping season 🎄.
Solution: Retrain your model periodically with new data.
Monitoring Metrics:
Even without labels, you can:
- Track changes in input feature distributions.
- Monitor confidence scores of predictions.
5. Exploding Gradients: What They Are and How to Fix Them 💥
Problem Explained:
When backpropagation computes overly large gradients, it destabilizes neural networks.
Solutions:
- Gradient Clipping: Cap gradients to a fixed max threshold.
- Batch Normalization: Normalize activations for stability.
- Architecture Tweaks: Use skip connections (e.g., in Transformer models) to soften dependency on deep layers.
Example: Exploding gradients often arise in RNNs due to long-term dependencies. Proper initialization and normalization can mitigate this.
6. Practical Tips to Build Robust Models 🛠️
Feature Scaling:
Normalize features to ensure stable optimization.
Classification vs. Regression:
Use regression for continuous values (e.g., predicting height) and classification for discrete categories (e.g., “short,” “medium,” “tall”). Pro Tip: You can bin continuous data into categories for easier learning.
7. AI Tools That Can Streamline Interview Prep 🤖
Tools like Ninjafy AI Check Out Here have changed how we prepare for ML interviews. They simulate real-time Q&A situations, refine your responses, and even detect where you can improve 💡.
How I Used Ninjafy AI:
During my Snapchat hiring journey, Ninjafy AI’s mock interview scenarios trained me to handle unexpected questions like concept drift with ease. Its personalization tailored feedback to my level and helped me confidently ace the technical round.
| Here are some alternatives: | Tool | Key Features | Ideal Use Case |
|---|---|---|---|
| Ninjafy AI | Personalized Copilot; Live AI Assistance | Comprehensive Interview Prepping | |
| Final Round AI | Mock interviews & simulations | Practice under pressure-rich scenarios | |
| Interview Warmup (Google) | Quick simulations for beginners | Build foundational interview confidence |

8. Final Thoughts 🤝
Mastering the nuance of Machine Learning interview topics like training data, hyperparameter tuning, and concept drift requires both technical understanding and strategic preparation. Tools like Ninjafy AI make this process seamless by bridging gaps in knowledge and sharpening soft skills.
Remember, no “one-size-fits-all” algorithm exists in ML. Your greatest weapon is your curiosity and ability to reason domain-specific solutions. Good luck with your next interview—your dream job awaits! 🌟✨

