Hey folks, this is John Carter, and today we’re diving deep into web crawling system design, the backbone of any search engine 🕵️♂️. If you’re a student, professional, or just a tech enthusiast, this guide will walk you through designing an architecture to handle a scale similar to search engines like Google and Bing. Plus, I’ll share some nifty insights I’ve picked up from FAANG engineers. Ready? Let’s roll 🚀.
What’s the Mission? Defining the Problem
The goal here is to design a distributed web crawling system that can handle modern web-scale data efficiently, support billions of queries daily, and provide up-to-date results to users. Think: building the skeletal infrastructure of Google Search, but tailored for a 10,000-machine setup 💻.
At its core, we’ll handle scraping, indexing, and result generation when a user queries something simple like “GDP statistics”. Sounds easy? Not so fast—when you talk about scale, things get 🔥 quickly.
Functional and Non-Functional Requirements
Functional 🚀
- Scraping URLs: Continuously retrieve links, structured content, and text data from websites.
- Indexing: Parse, clean, and rank content for efficient searches.
- Present Results: Given a query like “Python tutorials,” return relevant links ranked intelligently.
Non-Functional 💡
- Scalability: Handle 2 billion daily active users querying at 100,000 queries/sec 🚦.
- High Availability: Guarantee uptime even during scaling cycles.
- Acceptable Stale Data: Index may lag real-time data by hours or days (latest trends ≠ urgent).
- Storage Constraints: Efficient data compression & storage for billions of pages 📂.
Out of scope: Capturing real-time analytics, autocomplete, advanced query insights, and robots.txt parsing (though we could revisit these later).
Sizing It Up: Scale and Core Metrics
Let’s break down the numbers to understand our system demands:
| Metric | Value |
|---|---|
| Active Users (Daily) | 2 billion |
| Average Reads per User | 5 queries per day |
| Total Queries (Reads) | 10 billion per day (100,000 QPS) |
| Write Rate (Scraping) | 1,000 writes/sec for web crawlers |
| Average Web Page Size | 100 KB |
| Total Web Pages Stored | 20 billion (~2 PB of raw storage) |
Bandwidth Estimates
- Writes: 0.1 gigabytes/sec (=100KB * 1,000 w/s)
- Reads: 100 MB/sec (assuming 10 links/query)
Insight: Modern AWS instances like EC2’s M5 can comfortably handle these loads with efficient distribution. However, we’ll need over 20-1000 HDDs for storage. Key takeaway: hard disks add up fast, folks.
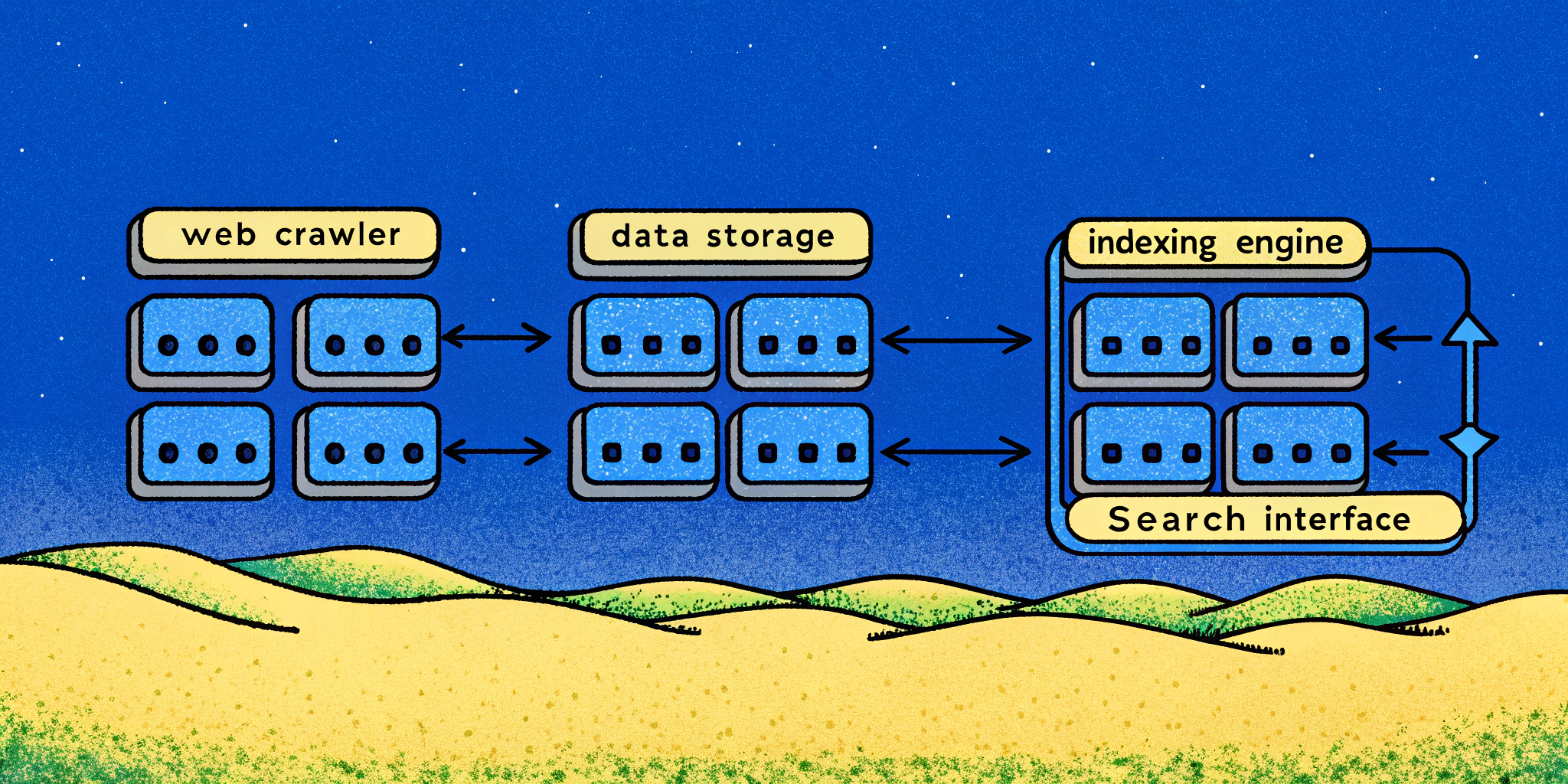
High-Level System Design
Picture this: the internet is a massive ocean 🌊, and our system is a small fleet of smart fishing boats. We’ll set up multiple distributed nodes doing the following:
- Fetch (crawl) URLs efficiently.
- Parse and extract metadata (e.g., publish date, links).
- Analyze and rank pages for search readiness.
- Serve user queries lightening fast ⚡ through efficient caching.
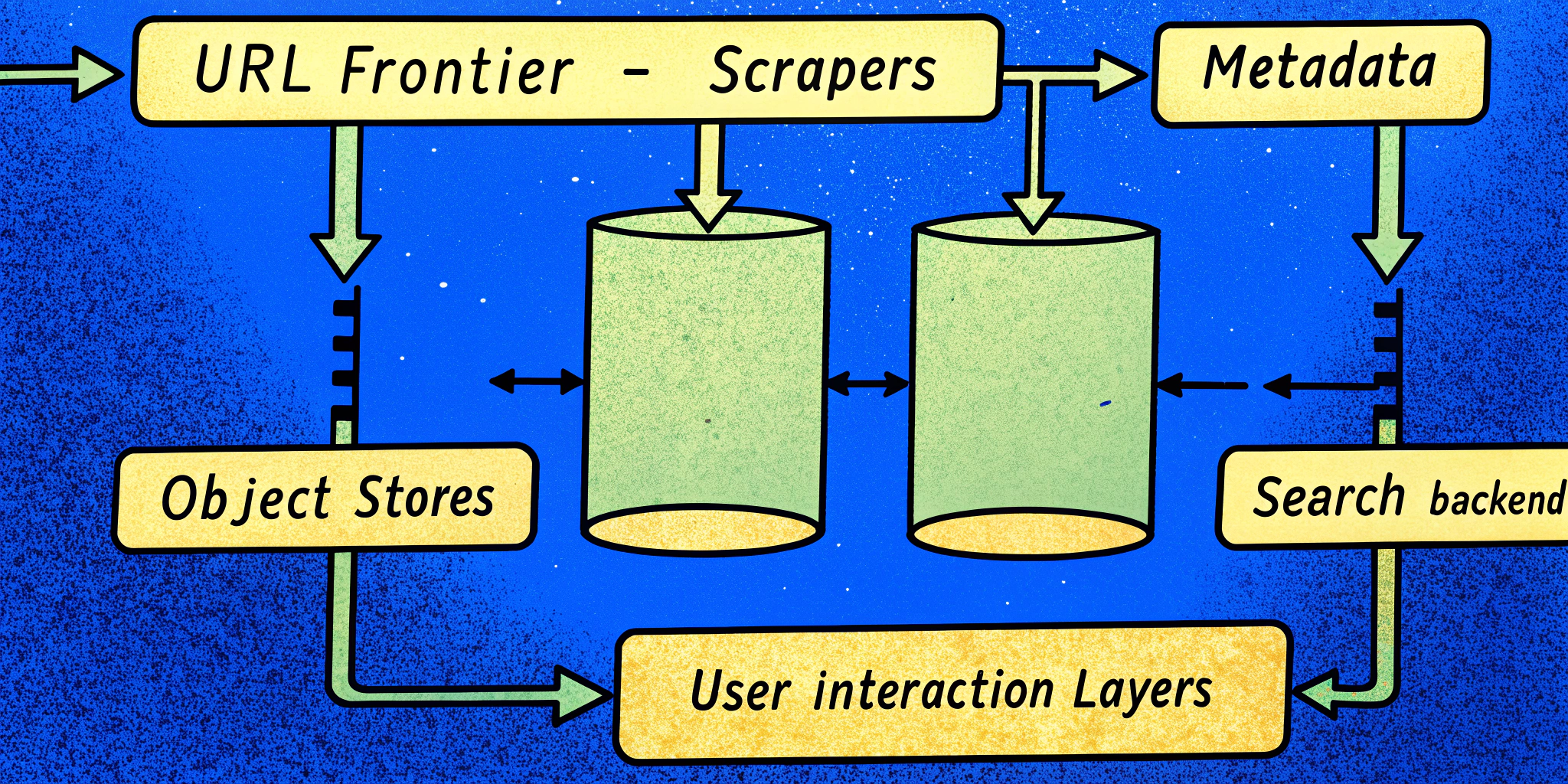
Key Components of Our Web Crawler
1. URL Frontier
The “to-do list” for web crawling tasks: store prioritized URLs needing immediate attention.
- Queue System: Kafka or RabbitMQ to manage millions of unvisited pages effectively.
- Domain Throttling: Avoid hitting friendly sites (e.g., Wikipedia) with thousands of requests/second (politeness policy 🙏).
- Adaptive Re-Crawling: Frequently update fast-evolving sites (e.g., news portals) over static pages.
2. Crawlers (Scrapers)
Distributed “robots” visiting sites, parsing the DOM, and saving raw pages to object stores.
- Writes: 1,000 pages/sec
- Output: Write to an object store like S3, and update metadata storage.
3. Metadata and Object Stores
Record basic info per page (URL, location in S3, last scraped timestamp). Helps ensure no duplicate crawls occur.
- Storage Example: 20 billion pages x 100 KB → 2 PB of baseline storage.
- Typical Formats: JSON, Compact Binary for metadata-efficient crawling.
4. Link Extraction Pipeline
Key to growing the database organically from interconnected pages.
- Graph Datastore: Build a web-link graph (vertices = pages, edges = link references).
- PageRank Algorithm: Precisely rank interconnected sites through iterative scoring (use Google’s Prego or MapReduce).
5. Ranking and Search Backend
The most critical component for query-time performance.
- Inverted Index: Maps keywords like “Walmart stock” → list of URLs containing terms with scores.
- Caching Popular Queries (Redis): For “hot” searches like breaking news topics.
Possible storage solutions include Redis for immediate results combined with DynamoDB for deeper, slower queries.
The Numbers Game: Storage, Bandwidth, and Machine Estimates
Here’s a calculator-style breakdown cutting through the noise:
| Resource | Requirement | Notes |
|---|---|---|
| Write Rate (Scraping) | 1,000 write/sec (1k TPS) | ~10 machines; bandwidth ≈ 0.1 Gbps |
| Storage Needs | 20-1,000 disks | For 20 billion pages (2 PB+) |
| Read Rate (Search) | 100k reads/sec (TPS) | Distributed across 100 backend nodes |
| Redis Cache (Popular) | ~20k queries/sec | Handles “hot” keywords. ≈ 2 machines. |
| Bandwidth Scalability | 0.8 Gbps | Similar to Twitter’s APIs scale ⚡. |
Advanced Insights: Lessons from Google’s MapReduce and Prego
Ever wondered how Google scaled its search system?
- MapReduce: Parallelized ranking computations across graph structures ⏩.
- Prego: Custom-built graph-processing batch jobs to handle page interlinks dynamically.
These fuel efficient scaling without breaking the bank on computational resources. (Pro tip: Read Google’s Prego whitepaper to achieve LinkedIn-level crawling experiments).
How to Handle Scalability Challenges
Stale Pages: Adaptive crawling. Scrape fast-moving targets hourly, but static ones monthly.
Reducing Costs: Minimize data duplication by compact formats + deduplicating interlink graphs.
Server Loads: Redis caching ensures 80-90% of queries avoid deep lookups.
Real-World Use Case: Can We Scrape LinkedIn?
Ah, the golden question 😏.
Technically, LinkedIn deploys bot defenses (anti-scraping) like CAPTCHA, rate-limiting, and IP-blocking. While possible, you’d need heavy-duty proxy rotation and distributed scrapers tuned for scale—and it’s ethically questionable 🫣.
Conclusion: Beyond the Crawlers
Congrats! If you’ve stuck with me, give yourself a pat; you’ve unpacked the essentials of running a scalable 10k machine web crawler. But let me leave you with this: getting great search is an iterative, people-based craft.
Looking to practice all this for real-world FAANG system design interviews? I’ve been blown away by Ninjafy AI, which supercharges mock interviews specifically on design problems, with guidance that molds to your industry. It simulated interviews for me when preparing for Amazon, and that personalized feedback shaved months off my prep time!
Don’t wait. Start scaling those dreams by simulating your next big interview 🔥.

